

Xai a présenté Grok 4 Fast, une version plus rapide et plus bon marché de son modèle le plus puissant à ce jour: Grok 4. Cependant, il a surpris par sa performance. Et il offre une performance par rapport à son prédécesseur, a un coût de 98% moins.
Selon la déclaration du propre entreprise De XAI sur son site Web le 19 septembre, la clé de sa légèreté et de ses performances se trouve dans une architecture qui unit les modes de « raisonnement » et « léger » sous un seul modèle. Autrement dit, nous allons mettre en service à la fois les tâches les plus complexes et les réponses les plus immédiates sans avoir besoin de changer de moteur.
Mais le plus important est qu'il arrive avec une fenêtre de contexte de 2 millions de jetons. Conçu pour gérer plus d'informations. C'est-à-dire que de longs documents, des enregistrements étendus ou des recherches travaillent avec une plus grande stabilité. Mieux encore, ce nouveau GROK-4-FAST met ses progrès au service de tous les utilisateurs, y compris les niveaux gratuits. Et il est déjà proposé sur le Web, les applications mobiles ou l'API. La question est de savoir si XAI réalisera, avec ce mouvement, rivalisera dans la qualité du prix de qualité contre les géants du marché: GPT-5, Gémeaux ou Claude.
Les nouveautés les plus importantes de Grok 4 Fast
Le nouveau modèle de la société d'IA sous les dirigeants d'Elon Musk vise à réduire les coûts sans couler la précision. En fait, Xai lui-même indique qu'il obtient des résultats comparables à ceux de Grok 4, mais réduit jusqu'à 40% les « jetons de pensée » nécessaires. Cela se traduit par une baisse jusqu'à 98% du coût pour obtenir les mêmes performances dans les tests de référence, selon la société elle-même.
En pratique, ces mouvements doivent être traduits en réponses plus rapides pour moins d'argent. Surtout si nous parlons de son utilisation via l'API ou des plans qui ont des jetons limites. Mais la chose la plus importante à propos de ce modèle est votre fenêtre de contexte de 2 millions de jetons. Le nombre de jetons est proportionnel à la quantité d'informations que le « mémorise » pour travailler avec elle. En fait, une fenêtre de 2 millions de jetons permet, par exemple:
- Traitez un roman de 500 pages à la fois pour analyser les archos narratifs et la cohérence.
- Vérifiez le code bases jusqu'à 100 000 lignes pour détecter les erreurs complexes.
- Analysez plus de 200 heures de transcriptions pour identifier les décisions et les modèles.
De cette façon, il est très utile pour travailler avec plusieurs documents, des conversations longues ou une analyse juridique et technique. Dans des contextes mineurs, lorsque vous travaillez avec de grandes quantités d'informations, il est habituel que vous deviez « couper » les informations afin de ne pas entrer en collision avec la limite de l'IA elle-même.
De plus, avec son architecture unifiée, il est capable d'échanger un raisonnement profond avec des réponses légères. Une tendance que nous voyons déjà dans des modèles comme GPT-5. Le modèle décide quand «réfléchir davantage» et quand retourner des résultats immédiats, en fonction de la simplicité de la tâche. Cette avance pour positionner Grok 4 rapidement en avance sur des modèles tels que GPT-5, avec 256 000 jetons, ou Claude 3.5, qui atteint 200 000 jetons.
| Modèle | Jetons de contexte | Différence contre Grok | Fontaine |
|---|---|---|---|
| Grok 4 Fast (xai) | 2 000 000 | Référence | Carte modèle xai |
| Gemini 2.5 (Google) | 1 000 000 | -50% | Blog Google AI |
| GPT-5 (Openai) | 256 000 | -87,2% | Rapport technique OpenAI |
| Claude 3.5 (anthropique) | 200 000 | -90% | Documentation anthropique |
Performance et disponibilité
Dans des comparaisons publiques telles que LmarenaGrok-4-Fast apparaît dans des positions très élevées pour les tâches de recherche, et également bien placée dans les tâches de texte. Ce qui signifie que les coupes ne proviennent pas d'une qualité drastique pour leurs utilisations les plus courantes.
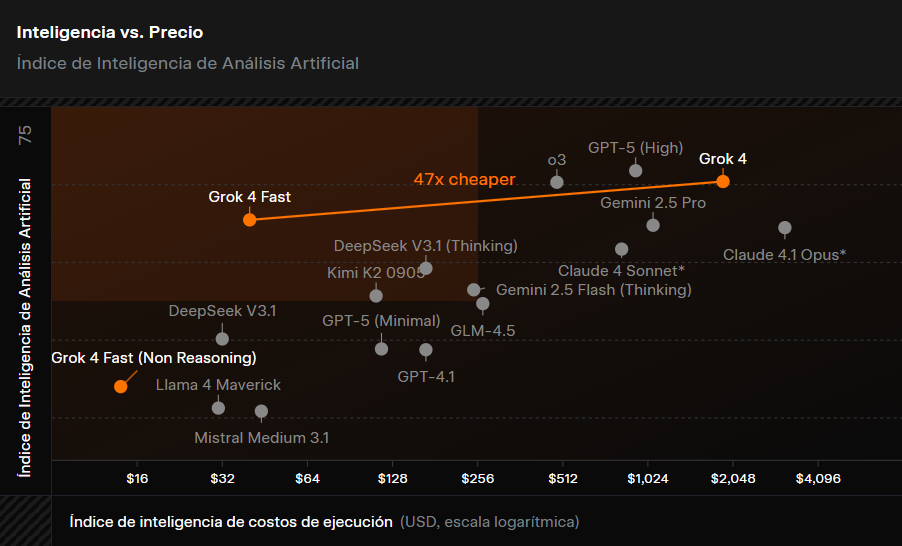
Dans le graphique, publié par le site Web X.AI, nous pouvons apprécier les différents modèles d'intelligence artificielle sous deux variables: leur capacité d'intelligence et son coût d'exécution. Dans ce cas, selon les résultats de cette analyse, Grok 4 Fast est celui qui obtient les meilleurs résultats dans la zone idéale (carré brun plus léger), suivi de Deepseek V3.1 (pensée) ou Kimi K2 0905.
Au-delà des repères, XAI le publiera de manière échelonnée pour tous les utilisateurs des applications Web et mobiles, ainsi que pour les utilisateurs de la plate-forme tels que OpenRouter ou Vercel AI Gateway.
| Fonctionnalité | Valeur | Impact direct | Fontaine |
|---|---|---|---|
| Fenêtre de contexte | 2 000 000 jetons | Analyse de documents de masse | Carte modèle |
| Réduction des coûts | 98% contre Grok 4 | Accessibilité pour les développeurs et les utilisateurs | Déclaration XAI |
| Réduction des «jetons de réflexion» | 40% | Réponses plus rapides et efficaces | Déclaration XAI |
| Architecture | Unifié (raisonnement / lumière) | Polyvalence sans changer de modèle | Carte modèle |
| Disponibilité | Web, applications et API (GRATUIT) | Démocratisation de l'accès à | Annonce officielle |